快速入门分布式系统与Dubbo+zookeeper Demo

分布式系统简述:
分布式系统(distributed system)是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。因此,网络和分布式系统之间的区别更多的在于高层软件特别是操作系统,而不是硬件。
(以下借鉴https://www.cnblogs.com/oxspirt/p/8663600.html中的一些理解)
分布式 —— 一个高大上的名词,只要遵循下述步骤即可将任何一个软件拆分为“分布式”的:
- 将你的整个软件视为一个系统(不管它有多复杂)
- 将整个系统分割为一系列的 Process(进程), 每个 Process 完成一定的功能
- 将这些 Process 分散到不同的机器上。分散后,选择若干种(没错一种可能不够)通信协议把他们连接起来
这就是分布式。把一个软件的各个模块拆分,到不容的机器上,用协议链接他们,让软件依旧可以正常使用就是分布式,
分布式的简单个人理解
其实分布式的定义十分的简单,我的个人理解就是:
话剧为例:若干个独立计算机的集合,但是他们只是在幕后集合,在荧幕前的观众(用户)看起来还是一个整体。
他通过网络协议通信为了完成共同任务,协调工作的计算机节点,每一个独立的计算机都是一个节点,由一个一个节点组成起来就是分布式系统。有点类似集群,但是分布式系统中,每一个节点都可以是一个集群,多设备代表着可以有更高的上限,性能,处理的信息量,。用更多的机器,处理更多的数据,
为什么你要使用分布式?
分布式系统并非灵丹妙药,解决问题的关键还是看你对问题本身的了解。通常我们需要使用分布式的常见理由是:
- 为了性能扩展——系统负载高,单台机器无法承载,希望通过使用多台机器来提高系统的负载能力
- 为了增强可靠性——软件不是完美的,网络不是完美的,甚至机器本身也不可能是完美的,随时可能会出错,为了避免故障,需要将业务分散开保留一定的冗余度
在以提供 Service 为主的服务端软件开发过程中常常遇到这些问题。
dubbo
文档地址:https://dubbo.apache.org/zh/docs/
随着互联网的高速发展,网站不断地扩大,我们的垂直应用架构无法应对,分布式服务架构以及流动计算架构势在必得,急需一个治理系统确保架构有条不紊的演进
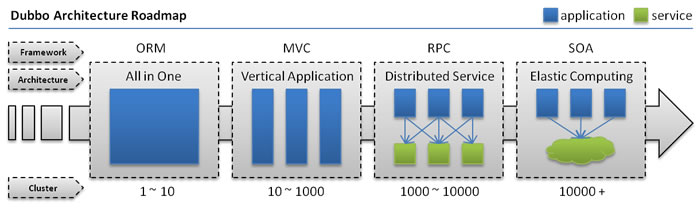
网站架构的迭代:
单一应用架构
当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的数据访问框架(ORM)是关键。

只有在极少用户的情况下可以使用,我们通过单体来一条线完成流程,但是访问的人数超过一定数量,就会出现问题于是乎,垂直应用架构出来了
垂直应用架构
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,提升效率的方法之一是将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的Web框架(MVC)是关键。
分布式服务架构
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式服务框架(RPC)是关键。
流动计算架构
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)是关键。
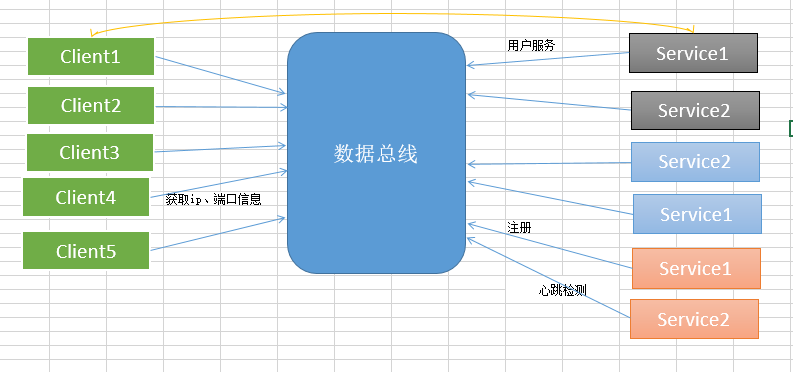
RPC
远程过程调用
以下理解转自:https://www.jianshu.com/p/7d6853140e13
什么是RPC?
简单的理解是一个节点请求另一个节点提供的服务
- 首先客户端需要告诉服务器,需要调用的函数,这里函数和进程ID存在一个映射,客户端远程调用时,需要查一下函数,找到对应的ID,然后执行函数的代码。
- 客户端需要把本地参数传给远程函数,本地调用的过程中,直接压栈即可,但是在远程调用过程中不再同一个内存里,无法直接传递函数的参数,因此需要客户端把参数转换成字节流,传给服务端,然后服务端将字节流转换成自身能读取的格式,是一个序列化和反序列化的过程。
- 数据准备好了之后,如何进行传输?网络传输层需要把调用的ID和序列化后的参数传给服务端,然后把计算好的结果序列化传给客户端,因此TCP层即可完成上述过程,gRPC中采用的是HTTP2协议。
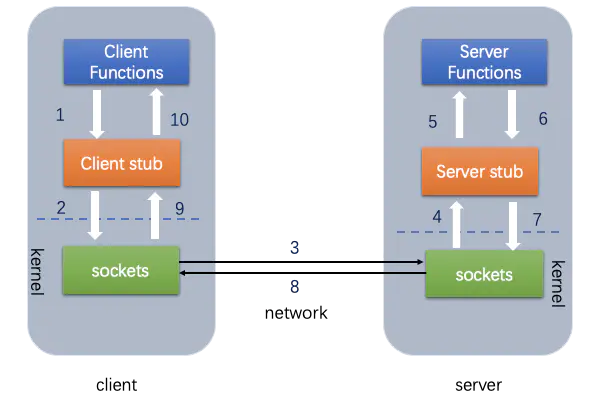
rpc两大核心模块:通讯,序列化
dubbo专注于RPC,专业的事情交给专业的人来做
dubbo是一款高性能RPC开源框架,它提供了三大核心能力:
- 面向接口的远程方法调用
- 智能容错和负载均衡
- 服务注册和发现
运行过程:
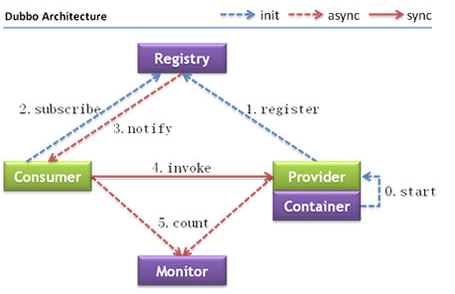
节点角色说明
| 节点 | 角色说明 |
|---|---|
Provider | 暴露服务的服务提供方 |
Consumer | 调用远程服务的服务消费方 |
Registry | 服务注册与发现的注册中心 |
Monitor | 统计服务的调用次数和调用时间的监控中心 |
Container | 服务运行容器 |
调用关系说明
- 服务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Dubbo 架构具有以下几个特点,分别是连通性、健壮性、伸缩性、以及向未来架构的升级性。
服务注册与发现
每日格言:
如果要挖井,就要挖到水出为止。
技术栈:
- springboot
- dubbo
- zookeeper
注册中心推荐zookeeper
下载链接:在3.5.5版本后,官方提供了bin的包,可以不需要配置环境,直接上手查看
https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
之后以管理员方式启动bin文件夹中的cmd文件
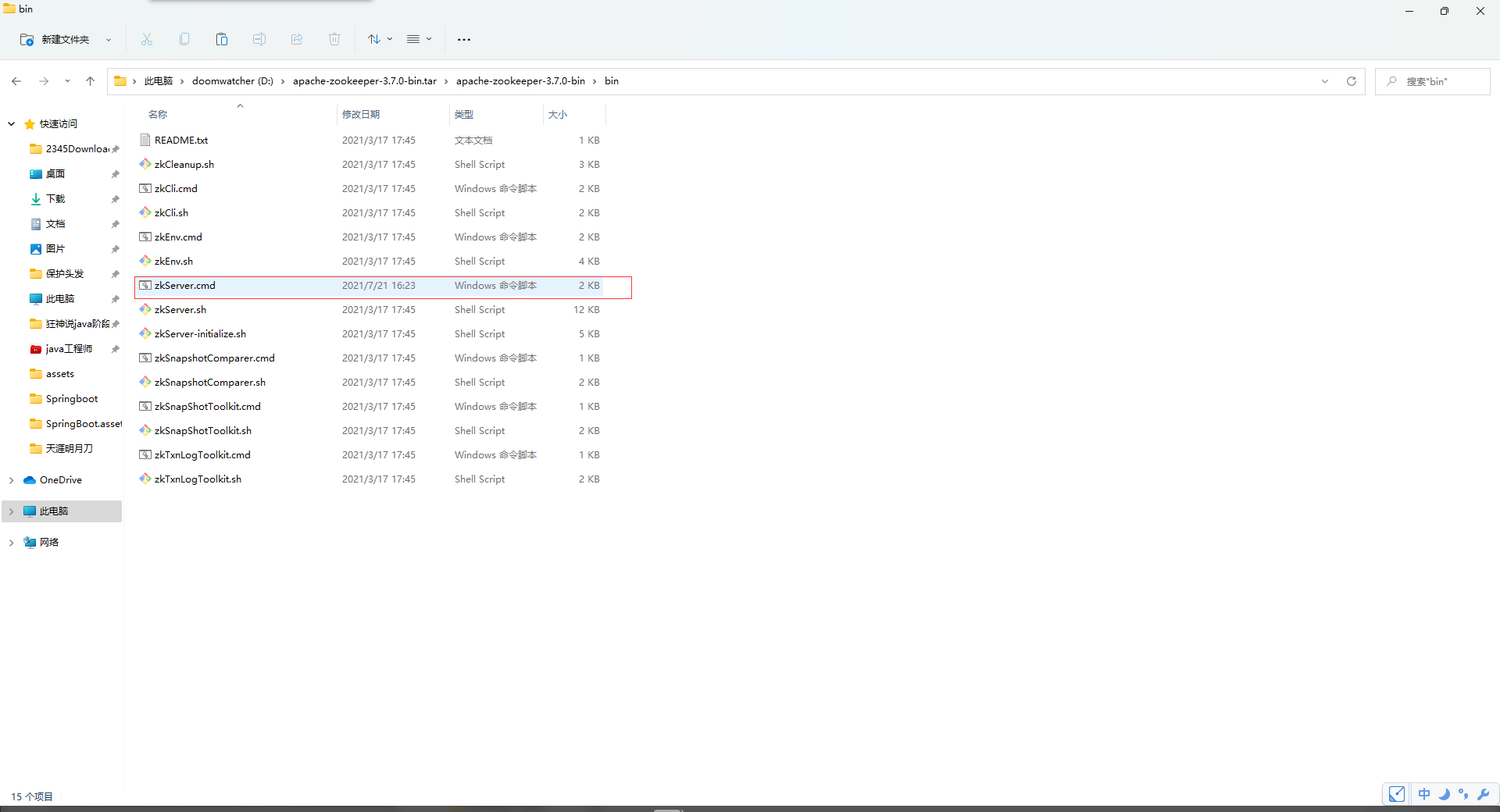
会报错,我们需要吧conf里的,zoo_simple复制一份,改成zoo.cof
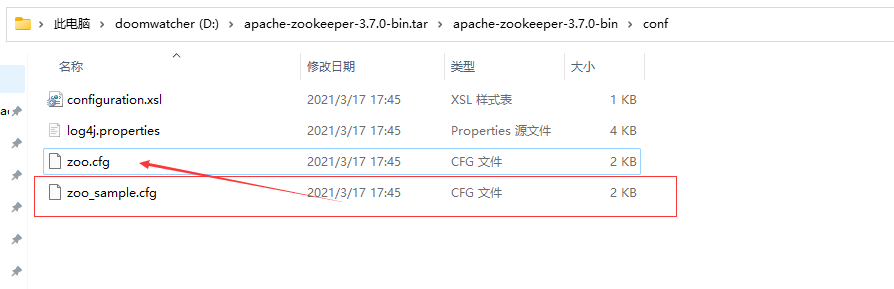
就可以了。linux版本的也一样
打开server和client之后,创建一个节点
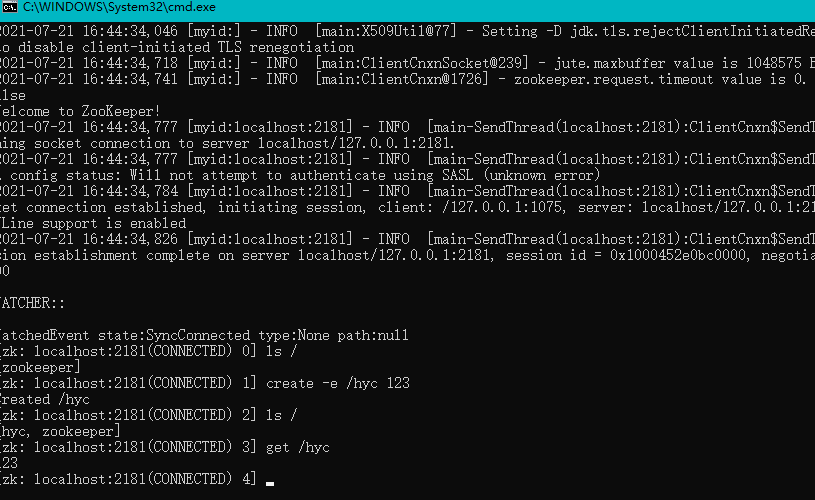
往里面放点东西:123
成功之后我们就可查看节点里的信息了
dubbo-admin
链接:https://github.com/apache/dubbo-admin
下载好之后,这个是dubbo的一个服务管理中心,可以看到我们注册的服务
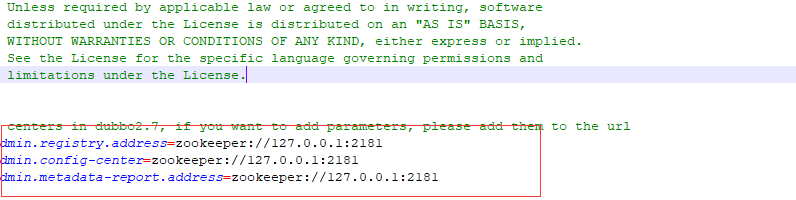
进入D:\dubbo-admin-develop\dubbo-admin-develop\dubbo-admin-server\src\main\resources下查看zookeeper的端口号2181,如果改动了,这里也要改
之后我们用cmd打开,mvn clean package -Dmaven.test.skip=true,打成jar包
过程可能有点慢,耐心等待
完成之后,把打包好的jar放入zookeeper根目录
之后先启动zookeeper,再跑jar包
查看是否连接成功
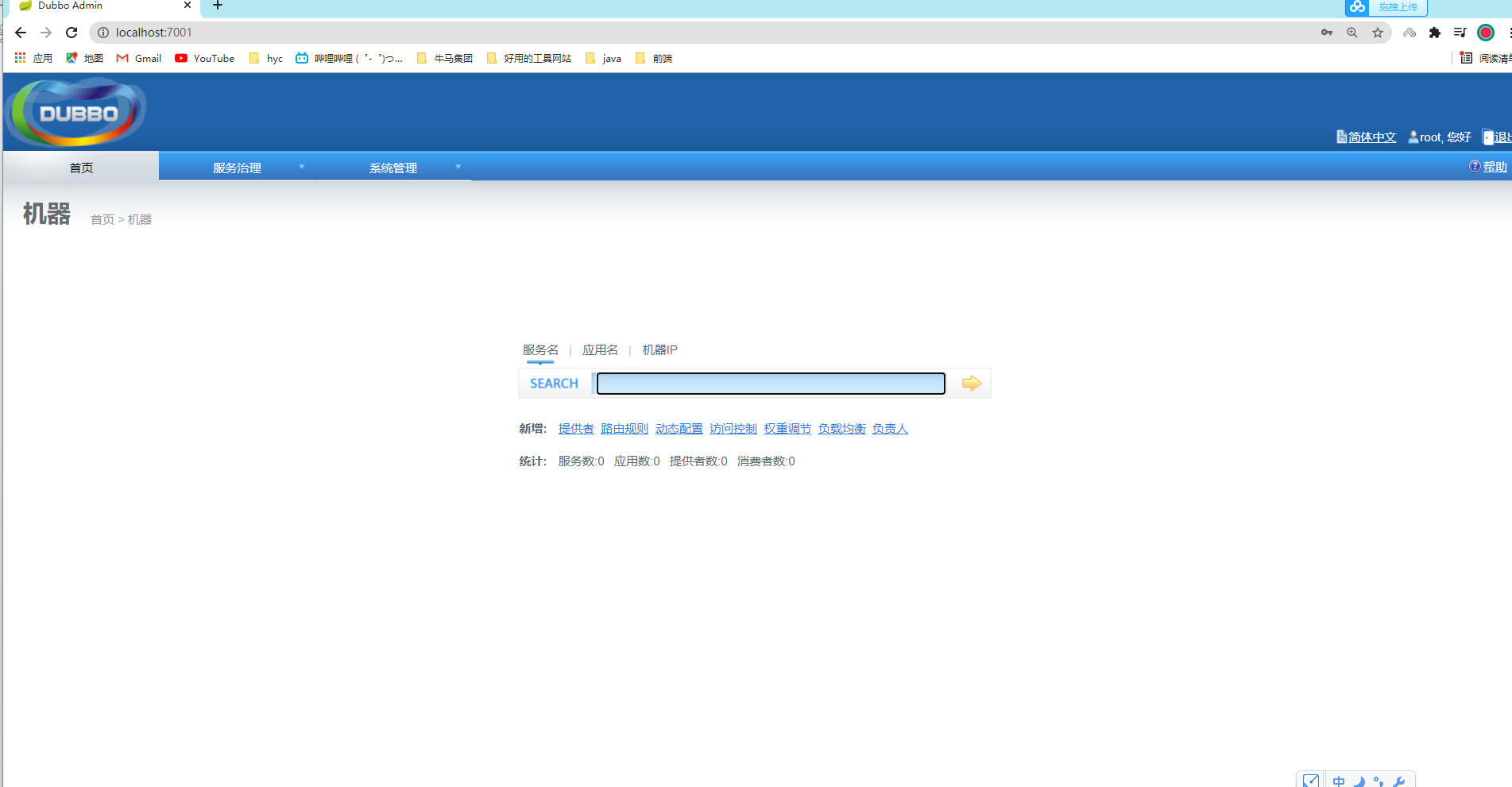
当当当!
前台,中台,后台
zookeeper:注册中心
dubbo-admin:是一个监控管理后台
Dubbo :jar包
那么我们要开始实战咯
服务注册与发现
我们建两个项目如下:

custom 端口配置为 8082
privoder 端口配置为8081
privoder依赖
<!-- https://mvnrepository.com/artifact/org.apache.dubbo/dubbo-spring-boot-starter -->
<!--dubbo-->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>2.7.12</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.github.sgroschupf/zkclient -->
<dependency>
<!--zkclient,zookeeper客户端--> <groupId>com.github.sgroschupf</groupId>
<artifactId>zkclient</artifactId>
<version>0.1</version>
</dependency>
<!-- 引入zookeeper 并且解决日志冲突-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.14</version>
<!--排除这个slf4j-log4j12-->
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
之后去设置服务者的配置文件
server.port=8001
#注册中心地址
dubbo.registry.address=zookeeper://127.0.0.1:2181
#服务名字
dubbo.application.name=privoder
#那些服务要注册
dubbo.scan.base-packages=com.hyc.privoder.service
在需要注册的服务上添加注解
@DubboService//在项目一启动就注册到注册中心
@Component//为什么不加service注解,应为dubbo的注册service,用于区分
public class ticketserviceImpl implements ticketservice {
@Override
public String getticket() {
return "hyc学微服务";
}
}
注册与发现就是zookeeper的作用
启动所有需要启动的服务
zookeeper--->dubbo的jar包 ---> 服务--->管理员网站服务查看
想拿到票,需要调用远程服务,拿到我们服务之者的方法,要去注册中心拿服务
我们先要配置的custom的配置,一样需要导入相关依赖。
编写配置文件:
server.port=8002
#要去哪里拿服务,需要暴露自己的名字
dubbo.application.name=custom
#注册中心地址
dubbo.registry.address=zookeeper://127.0.0.1:2181
之后我们需要调用本地的Autowired是本地调用,我们这里远程调用@DubboReference
@Service//这里要用spring的注解哟,只有spring可以字自动装配
public class UserService {
//想拿到票,需要调用远程服务,拿到我们服务之者的方法,要去注册中心拿服务
@DubboReference//引用 Pom坐标可以定义路径相同的接口名
ticketservice ts;
public void buyTicket(){
String getticket = ts.getticket();
System.out.println("注册中心拿到"+getticket);
}
}
如果报错就降级启动器,解决
记得要在统一包下的服务,
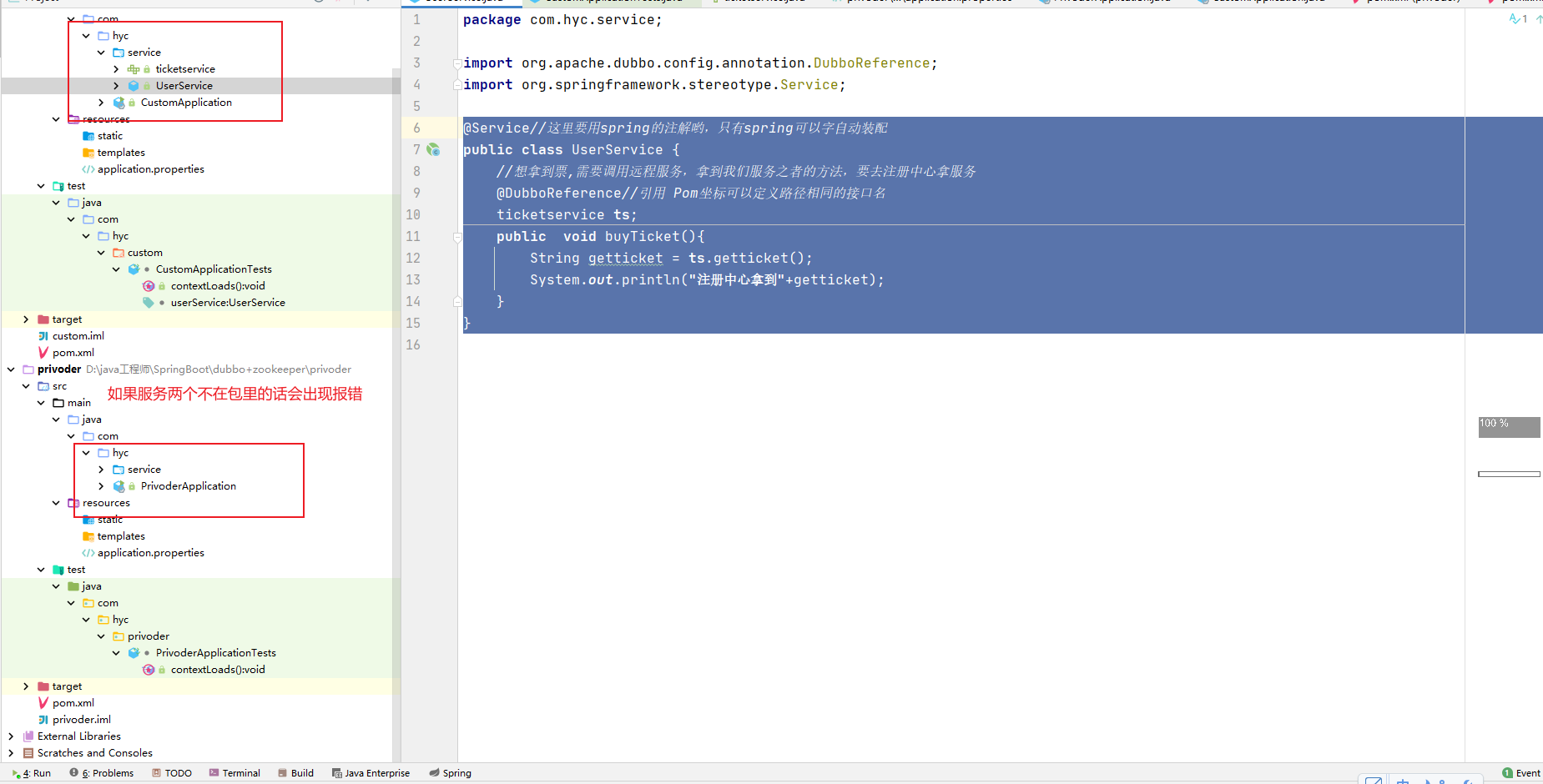
步骤:
- 提供者服务
- 导入依赖
- 配置文件,注册中心地址,服务发现名和要扫描的服务
- 想要被注册的服务上加上dubbo的service注解和spring的compent组件
- 消费者如何消费
- 导入依赖
- 配置文件,服务发现名,注册中心地址
- 我们需要在客户端建立一个一样的服务者接口,直接远程注入就可以使用这个服务的方法了,远程调用注解@DubboReference
到这里简单的服务注册与发现的使用就完成啦,